As part of an autonomous drone project I’m working on, I created a program which displays the drone’s position and orientation in real-time. This program required a mechanism to manage the flow of data coming from a telemetry receiver.
To address this, I implemented a thread-safe bounded buffer in C++ with multiple interfaces to satisfy different use-cases. The data structure is fully tested with GoogleTest and is available on Github as a header-only library.
This post discusses the background and motivation of bounded buffers, along with some of the requirements for an implementation and necessary multithreading concepts. The next post, part 2, will dive into the buffer’s interface and implementation.
Producer/Consumer Pattern
Before discussing the bounded buffer itself, let me first explain the main scenario in which bounded buffers can be useful. The producer/consumer pattern is a general software pattern which describes the interaction between two parties, a producer and a consumer.
Consider the following real-world scenario: A donut shop (the producer) generates donuts continuously while customers (the consumers) purchase donuts throughout the day. The donut shop uses traffic from previous days to predict how many donuts are needed at different times of the day. That being said, the customers themselves are still fundamentally unpredictable and as a whole they do not purchase donuts at some strict rate. The shop uses racks to store the donuts, which are being emptied and replenished continuously.
In this example, we have the following elements:
- Resource: Donuts
- Producer: Donut shop
- Consumer: Customers
- Storage mechanism: Donut racks
This is a producer/consumer situation. Resources are generated and used by various parties, while some mechanism holds the resources awaiting consumption. Resources can be produced/consumed at fixed rates, intermittently, or both. Multiple producers and/or consumers may be present.
The producer/consumer problem arises in multiple areas of software. Some examples:
- An operating system sending and receiving packets through network interfaces
- A hardware device passing received data to a software application for processing, such as a thermostat passing temperature data to a home automation system
- A game server receiving data from multiple clients and updating the game environment accordingly
Bounded Buffers
In the above donut shop scenario, the donut racks serve as a literal buffer between the donut-making machines and the customers. They also happen to be bounded by their size, which determines how many donuts they can hold. They allow for discrepancies between the production and consumption rates inherently present in the system. In the same way, bounded buffers are used to solve the general problem related to mismatched production/consumption rates among multiple parties.
In practice, a bounded buffer is just a queue with specific input/output properties. Let’s look at a graphical representation of a bounded buffer:
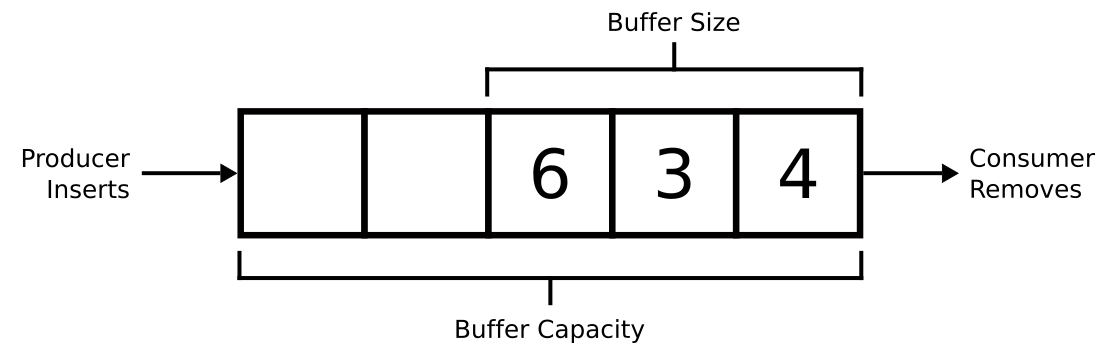
First, the buffer has a capacity which defines the maximum number of elements that can be stored. This is why the buffer is called bounded. The size of the buffer, in keeping with the terminology of C++’s standard containers, is the current number of elements in the buffer.
Since the buffer is a queue, elements are removed in the same order that they were placed into it: first in, first out (FIFO). Multiple producers and multiple consumers are permitted. Producers may only insert elements into the buffer, while consumers may only remove elements from it.
Bounded Buffer Input/Output
Bounded buffers have a few complications, the first of which is controlling producer/consumer access to the data. When a buffer is just partially full, this is straightforward because data can be inserted or removed without issue. The problem arises when attempting to add data to a full buffer or remove data from an empty buffer.
Remembering the donut shop example, what should be done when more donuts are made than can be held in the storage racks? Conversely, what should a customer do when no donuts are available in the storage racks? To answer the first problem, the theoretical solutions are:
- Discard the extra donuts
- Pause the donut assembly line indefinitely until space is available
- Wait some finite amount of time for space to become available, but start throwing donuts out when that time passes
- Discard the oldest donuts from the racks to make space for the newer donuts
In real life, these approaches may not be sufficient. In an actual donut shop, additional solutions would likely be employed. More storage would be used, donut production would be slowed, and donut production would likely be slowed under in the future to prevent the problem from occurring again. These additional measures may or may not be under one’s control in a software system, but regardless they are separate from the bounded buffer itself. Thus, we will stick to these four solutions.
Now let’s look at a customer’s options when no donuts are ready:
- Leave the donut shop
- Wait indefinitely for donuts to become available
- Wait a finite amount of time for donuts to be ready, leave once this time passes
These options correspond to the first three producer’s options, since the fourth is not possible from the consumer’s perspective.
Finally, let’s map these donut shop options to those for a bounded buffer:
Producer:
- Do not add the element and mark the operation as failed
- Wait until there is space to add the element
- Wait some set amount of time for space to be created, fail if the time expires
- Create space by removing an element, then add the element
Consumer:
- Do not remove any elements and mark the operation as failed
- Wait until an element is present
- Wait a set amount of time for an element to be available, fail if the time expires
These options are all implemented in the bounded buffer I created. This will be discussed more in part 2.
Race Conditions
Another complication regarding bounded buffers is that of race conditions. A race condition occurs when multiple threads “race” to access a resource at the same time. If two threads are attempting to execute a function at the same time, it’s possible that one function will start executing while the other is already running. This can lead to incorrect results if not disallowed. Take the following function (interpret it, and the remaining code in this section, as pseudocode):
int global_val;
void increment_global()
{
int tmp = global_val;
tmp++;
global_val = tmp;
}If two threads were to execute the function at the same time, the results should look like this:
int global_val = 1;
int tmpA = global_val (1); // thread A
tmpA++ (2); // thread A
global_val = tmpA (2); // thread A
int tmpB = global_val (2); // thread B
tmpB++ (3); // thread B
global_val = tmpB (3); // thread B --> correct value!Either thread A or B could be executed first, but the main point is that one thread should run to completion before the next starts executing. But as it stands, the results could look like this:
int global_val = 1;
int tmpA = global_val (1); // thread A
int tmpB = global_val (1); // thread B
tmpA++ (2); // thread A
tmpB++ (2); // thread B
global_val = tmpA (2); // thread A
global_val = tmpB (2); // thread B --> wrong value!Instead of thread A running to completion before thread B starts, the code of
the two functions could become interleaved. This would cause thread B to use the
wrong initial value for global_val (1) instead of the intended value (2). To
be clear, the issue is not quite that two of the same function are being run
in parallel - the problem could arise if the two threads were running different
functions. The real problem is that both threads access the same shared data
(global_val) without any restrictions. Some kind of access control must be
provided for the shared data. This is achieved with a lock, also called a
mutex (short for mutual
exclusion).
A mutex can be compared to the lock on a porta potty. When approaching the stall, you first check the condition of the lock. If the lock is red, it means that someone is already using the toilet and you must wait. If the lock is green, the stall is unoccupied and access can be obtained. Claiming a porta potty for oneself requires more than just walking in and closing the door, though. Upon entering the bathroom you must lock the stall, setting it to the occupied state so others know not to enter. Mutexes are similar in the sense that they are technically optional and may not always end up being required (for example, maybe no one tried to enter the bathroom while you were using it). Not using them, however, can result in some unfortunate situations.
There is some additional terminology concerning mutexes. They are said to be acquired and released when a thread obtains them or gives them up (locking and unlocking the bathroom stall, accordingly). Their operation is also said to be atomic, which means that no instructions from other threads can interrupt their operations. Operations including “normal” data types like regular Booleans are not atomic and thus cannot guarantee the prevention of race conditions like mutexes can (read more about this here and here).
If we require that a lock be obtained before acting on a shared resource, then every instruction is safe while the lock is held. This enforces the following scenario, consistently (more pseudocode):
int global_val = 1;
mutex global_val_mtx;
// both threads attempt to acquire the lock, thread B succeeds (could have been
// thread A)
lock(global_val_mtx); // thread B
int tmpB = global_val (1); // thread B
tmpB++ (2); // thread B
global_val = tmpB (2); // thread B
unlock(global_val_mtx); // thread B
lock(global_val_mtx); // thread A
int tmpA = global_val (2); // thread A
tmpA++ (3); // thread A
global_val = tmpA (3); // thread A --> correct value!
unlock(global_val_mtx); // thread AAll of this discussion is to say the following: a bounded buffer requires a mutex in order to be considered thread safe. This means that multiple threads can use the bounded buffer simultaneously without causing any problems due to race conditions. Because of the scenarios bounded buffers are used in, thread-safety is often a requirement.
Condition Variables
For bounded buffers, there is one additional construct required for correct operation. This is called either a signal or a condition variable. Condition variables allow threads to communicate to each other that some condition has been met.
In a bounded buffer, this is necessary when one or more consumers are waiting for data to be placed into an empty buffer. After executing a wait command, each consumer thread is put into a queue corresponding to the shared condition variable it is waiting on. When the condition variable is notified, the next consumer thread is allowed to run. Producer threads manually notify the condition variable after putting data into the buffer. The condition variable then wakes up the next waiting consumer thread automatically.
Waiting on a condition variable is in contrast to a polling strategy. In a polling strategy, the next waiting consumer thread in the queue would continuously check the status of the buffer. Once it finds an available piece of data in the buffer, it starts running. This is more wasteful of CPU cycles since polling requires the thread to be actively doing something, while condition variables allow the thread to be put to sleep.
Remembering back to the donut shop example, the waiting strategy is akin to customers sitting down and waiting for donuts to become available if none are ready. Once a donut is made, the customer waiting the longest is alerted. The polling strategy, on the other hand, corresponds to the next customer repeatedly checking whether donuts are ready.
The same pattern works in the other direction: producer threads are also put into their own queue when the buffer is full, while consumer threads notify a second condition variable when empty space becomes available in the buffer. To be explicit, the bounded buffer contains two thread queues and two condition variables:
- One queue to store waiting consumer threads
- One condition variable to notify data is available in the buffer
- One queue to store waiting producer threads
- One condition variable to notify empty space is available in the buffer
Conclusion
Now that we’ve covered the motivation for implementing bounded buffers and some of the high-level features associated with them, we are ready to get into the weeds of an actual implementation. That will be covered in part 2. We will discuss the API design, the C++ implementations of mutexes/condition variables, and the source code of some of the bounded buffer functions.
Here’s the repository. Suggestions and pull requests are welcome.